Introduction
Pong is a classic game, a very abstract version of Ping-Pong, where two paddles attempt to reach a ball before it falls off the table. It looks like this:
The goal of mastering the game of Pong is to learn a policy. A policy is a mapping from the state of the game to an action. The state of Pong is an 8-dimensional vector describing the position of the ball \((x,y)\) and its velocity \((v_x,v_y)\), as well as the position and velocity of the two paddles. The actions are \(\{\text{STAY}, \text{UP}, \text{DOWN}\}\). So a policy is simply a function \(\pi:\mathbb{R}^8 \to \{\text{STAY}, \text{UP}, \text{DOWN}\}\), and we try to find a good policy.
In the video above you can see two simple policies we programmed manually: the “Follow” policy on the left, which attempts to follow the ball at all times (similar to what a person might do), and the “Predict” policy that simply calculates the position where the ball will hit the relevant end of the table and goes there.
It might be useful to make a distinction here between three kinds of games:
- Snake-like games, where there is a single agent acting in (or against) a constant environment. We deal here mostly with this kind of game, by fixing the left paddle to the “Follow” policy, and learning only the policy for the right paddle.
- Pong-like games, where there are two or more symmetric agents. This is a different problem. A possible solution is to learn the policies for both sides, hoping that the competition between the learners will allow them to gradually improve. Because those games are symmetric, we can use the same policy for both sides.
- Fox-like games (such as Bagh-Chal/Tafl), where there are two or more asymmetric agents. We won’t cover such games here.
Deep Reinforcement Learning
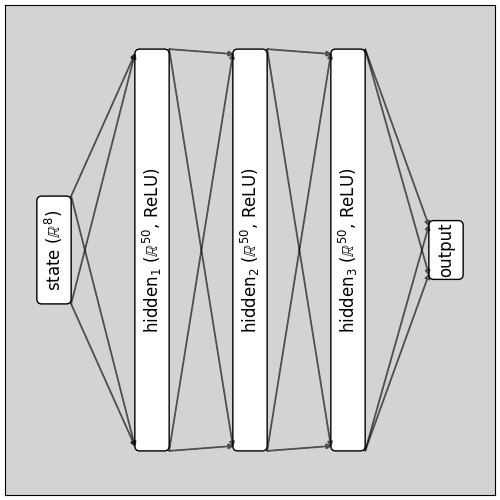
As mentioned previously, we relied on deep learning as a building block inside RL algorithms. In all of our experiments, we used the same Neural Network (NN) architecture: 3 hidden layers with 50 ReLU units each. It was a completely arbitrary choice that turned out to be good enough. We used the Tensorflow implementation of AdamOptimizer using its default parameters.
Our goal is not to develop the best RL algorithm, but to compare some different common algorithms and understand their relative strengths and weaknesses. It means that we didn’t optimize any of the hyper-parameters of deep learning and of the RL algorithms. We did tweak them a bit when it was necessary in order to make them work, but we tried to do as little of that as possible.
Our Code
The code is available in github, as well as usage instruction and (some) documentation. You are more than welcome to download it, test it yourself and implement your own variations on those algorithms. Here are some general useful commands:
python play.py # play using the arrows against “Follow”
python play.py -r predict # watch games between “Follow” and “Predict”
python learn.py algorithm -sp /path/to/model # Learn using algorithm, saving in /path/to/model
python play.py -r nn -ra /path/to/model # watch games between “Follow” and a learned policy
python match.py -r nn -ra /path/to/model # perform 100 games between “Follow” and a learned policy and print their results.
Next Chapter
Now that we’re all on the same page, you should move on to Chapter 1: When You Have an Expert, where we describe perhaps the simplest approach to RL.